
Algorithms
reinforcement learning (adaptive control)
The reinforcement algorithm we implemented was from Marco Weiring's "Multi-Agent Reinforcement Learning for Traffic Light Control." Reinforcement learning in this case comes from Q-learning theory, implementing a machine learning algorithm which uses a reward function as reinforcement.
The algorithm calculates the cumulative waiting time for each car at a given intersection, by calculating the probability of a car's position in the future given the current traffic light is either red or green for each road. This probability comes from the P-function, which gives an estimate of the probability of each car reaching any other cell.
This P function is used to calculate the Q-function, which recursively defines the cumulative waiting time using the V-function. This V (value) function gives a weighting of the relative benefit of a traffic light's decision for each car. This is taking into consideration the current timestep as well as all future times for that car. The V-function uses the P-function's description of movement probabilities at the current and future time interval to find which light decision (red or green) would benefit each car.
The algorithm calculates the cumulative waiting time for each car at a given intersection, by calculating the probability of a car's position in the future given the current traffic light is either red or green for each road. This probability comes from the P-function, which gives an estimate of the probability of each car reaching any other cell.
This P function is used to calculate the Q-function, which recursively defines the cumulative waiting time using the V-function. This V (value) function gives a weighting of the relative benefit of a traffic light's decision for each car. This is taking into consideration the current timestep as well as all future times for that car. The V-function uses the P-function's description of movement probabilities at the current and future time interval to find which light decision (red or green) would benefit each car.
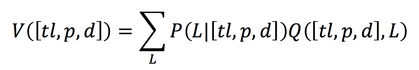
Along with the V-function, the R (reward) function is used in the calculation of the Q-learning algorithm. The Reward function is described by a given reward of 0 for movement and 1 for staying still. It is a goal of the algorithm to minimize this reward function, and through this it will learn to minimize the amount of time cars are stuck in a standstill.
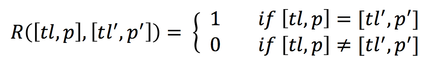
Future timesteps are discounted to ensure that the Q-function value converges for each car and to consider the relative uncertainty of decisions farther into the future. The Q-function takes in the Reward and Value functions and recursively generates an estimate for the additional waiting time a respective traffic light decision will add to the system. When the algorithm runs, it produces a waiting time for each of the possible decisions a traffic light makes. These values are used by the light to pick a decision for each timestep.
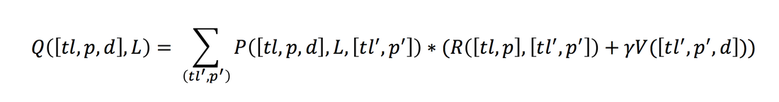
Once the waiting time for every car waiting at the intersection is calculated and summed for each of the two queues, the traffic light will dynamically decide which road should have a green and which side red.It does this by picking the option that minimizes the Q-function, the light scenario (Road 1 = red & Road 2 = green or Road 1 = green & Road 2 = red) by the situation whose calculated probabilistic waiting time is the least.
This decision will change based on the dynamics of the system. As the Q-function is a machine-learning algorithm that learns based on the results of "games" that are played (a game as used in game theory), the algorithm will converge to the optimal solution a few cycles (timesteps) after the new dynamics are realized. In our algorithm, the function would re-optimize when the dynamics were changed in as few as 4 timesteps.
A machine learning approach is best when the state of the system changes often and/or unpredictably. Traffic control is a perfect application of reinforcement learning as the state of the system is indeed prone to rapid change. Accidents, rush hour, and weather changes can cause the cars in the system to behave very differently than they would without these hindrances. A traffic controller that is not able to learn from the system would be forced to consider each of these cases separately and program the traffic lights to react to these specific changes. Not only is this time consuming, but it is unlikely that each and every possible case will be considered and those that are will not necessarily have algorithms are optimal for their specific case.
With an unpredictable, stochastic system such as traffic, it is best to leave the decisions to an algorithm that can figure out optimality on its own. If you look at the results section, you will see that the learning algorithm does just that.
This decision will change based on the dynamics of the system. As the Q-function is a machine-learning algorithm that learns based on the results of "games" that are played (a game as used in game theory), the algorithm will converge to the optimal solution a few cycles (timesteps) after the new dynamics are realized. In our algorithm, the function would re-optimize when the dynamics were changed in as few as 4 timesteps.
A machine learning approach is best when the state of the system changes often and/or unpredictably. Traffic control is a perfect application of reinforcement learning as the state of the system is indeed prone to rapid change. Accidents, rush hour, and weather changes can cause the cars in the system to behave very differently than they would without these hindrances. A traffic controller that is not able to learn from the system would be forced to consider each of these cases separately and program the traffic lights to react to these specific changes. Not only is this time consuming, but it is unlikely that each and every possible case will be considered and those that are will not necessarily have algorithms are optimal for their specific case.
With an unpredictable, stochastic system such as traffic, it is best to leave the decisions to an algorithm that can figure out optimality on its own. If you look at the results section, you will see that the learning algorithm does just that.
